The Universal Language of AI: Evolution of Embedding Models
"Go beyond the prompt. Discover the mathematical magic of embeddings, from contextual text models to multimodal spaces, ColBERT, and Matryoshka Representation Learning."
If Prompt Engineering is how we talk to AI, and Context Engineering is how we manage its memory, then Embedding Models are the underlying physics engine that makes it all possible.
Large Language Models (LLMs) do not understand English, Spanish, or Python. They only understand math. Embeddings act as the universal translator, converting complex, high-dimensional human data—like text, images, and audio—into dense vectors of real numbers.
But what exactly is an embedding? How do different models map human language into mathematical space? And what are the cutting-edge techniques pushing the boundaries of Retrieval-Augmented Generation (RAG)?
Let’s take a deep dive into the vector space.
What is an Embedding? (The “Library” Analogy)
Imagine a massive, infinitely large library. If you drop a new book into this library randomly, you will never find it again.
Instead, you organize the library semantically. You place Harry Potter next to The Lord of the Rings because they share themes of fantasy and magic. You place an astrophysics textbook miles away on a different floor. But wait—Dune is both sci-fi and fantasy, so it needs to sit exactly halfway between the astrophysics textbook and Harry Potter.
An embedding model does this exact sorting process, but in a mathematical space with hundreds or thousands of dimensions. It assigns a coordinate (a vector) to every piece of data.
- Data with similar meanings are plotted close together.
- Data with unrelated meanings are plotted far apart.
This allows computers to instantly calculate the “semantic distance” between two concepts. It’s why an AI knows that the famous equation King - Man + Woman ≈ Queen is mathematically true in vector space.
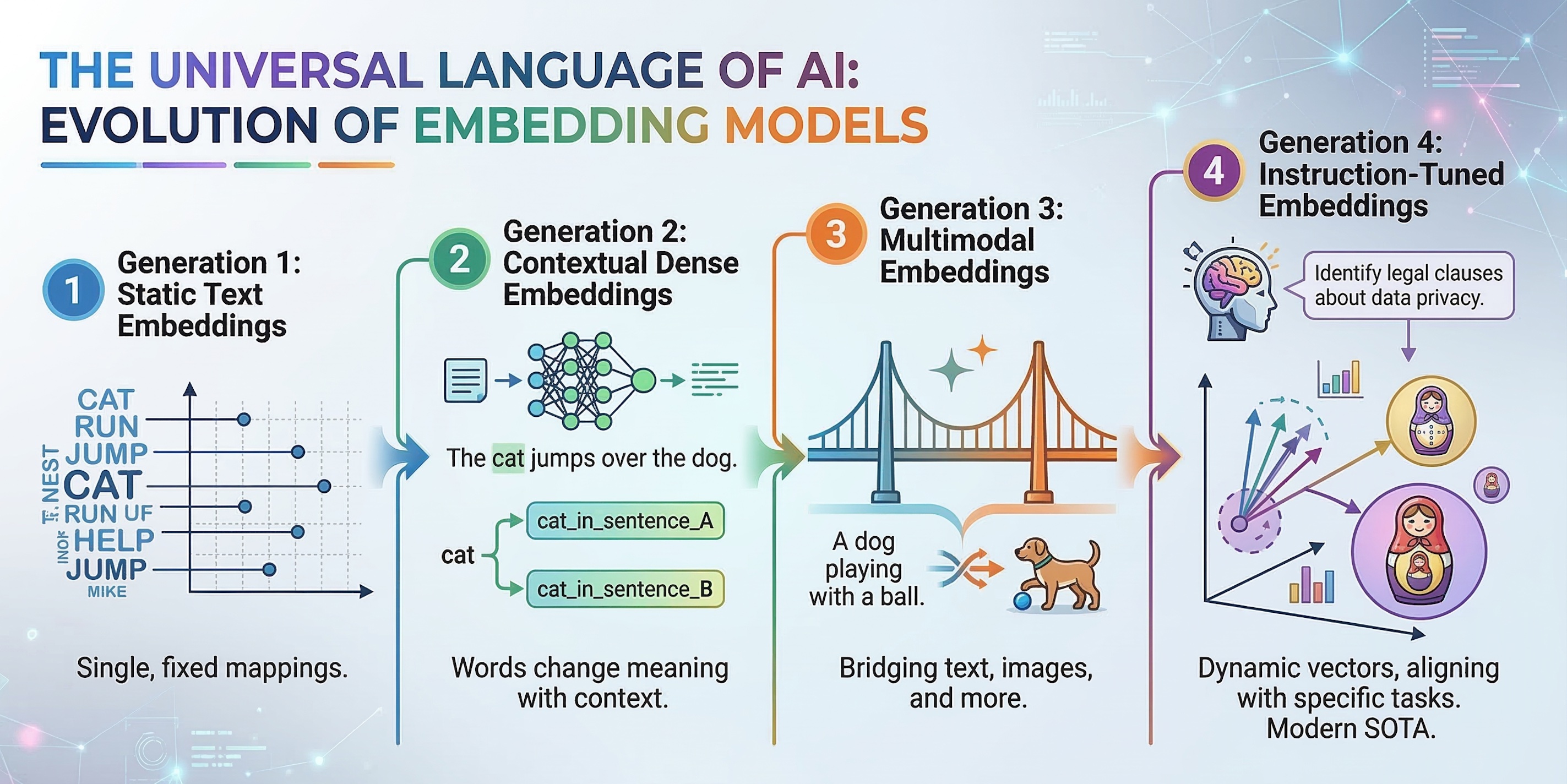
The Evolution: Types of Embedding Models 🗺️
Embedding models have evolved rapidly over the last decade. Here is the spectrum from the basics to the state-of-the-art.
Generation 1: Static Text Embeddings (The Pioneers)
Examples: Word2Vec, GloVe Early models assigned a single, fixed vector to every word in the dictionary.
- How it works: It looks at a word and maps it to a coordinate based on its historical usage.
- The Weakness: It cannot understand context or polysemy (words with multiple meanings). To a static model, the word “bank” has the exact same coordinate in “I sat by the river bank” and “I opened a bank account.”
Generation 2: Contextual Dense Embeddings (The Standard)
Examples: BERT, Sentence-BERT (SBERT), OpenAI text-embedding-ada-002
This generation changed everything by using Transformer architectures.
- How it works: Instead of looking at a word in isolation, the model reads the entire sentence. It passes the text through multiple layers of “attention,” outputting a single, pooled vector that represents the overall meaning of the sentence.
- Strengths: Highly accurate semantic understanding. It knows that “river bank” and “bank account” are completely different concepts.
- Weaknesses: They compress entire documents into a single vector, which can cause them to lose fine-grained, highly specific keywords (like a unique product ID or a rare name).
Generation 3: Multimodal Embeddings (The Bridge)
Examples: OpenAI CLIP, Meta ImageBind Why restrict the vector space to just text? Multimodal models map entirely different types of data into the same mathematical space.
- How it works: A model like CLIP has two encoders—one for text and one for images. During its creation, it learns that the vector for a picture of a Golden Retriever should be placed at the exact same coordinate as the text “a photo of a Golden Retriever.”
- When to use: Image search, zero-shot classification, and cross-media retrieval (e.g., searching for a specific podcast moment using a text query).
Generation 4: Instruction-Tuned Embeddings (The Modern SOTA)
Examples: BGE-Large, Voyage AI, Cohere Embed v3 Modern embedding models don’t just encode text; they encode intent.
- How it works: You prepend an instruction to your data, like
"Represent this sentence for searching relevant passages: [TEXT]". The model dynamically alters the vector placement based on what you intend to do with it (clustering, classification, or retrieval).
Advanced Architectures
If you are building enterprise-grade search or RAG, standard dense embeddings are often not enough. Here are the advanced techniques dominating the industry today.
1. Late Interaction Models (ColBERT)
The cure for the “Lost in Compression” problem.
Standard embedding models use Early Pooling: they crush a 500-word document into one single vector. If a user searches for a highly specific phrase buried in paragraph three, a single vector might miss it.
ColBERT (Contextualized Late Interaction over BERT) fixes this:
- Instead of creating one vector per document, ColBERT creates a separate vector for every single token (word) in the document.
- When a user submits a query, it also generates a vector for every token in the query.
- It then performs “late interaction,” matching each query token to the most similar document token.
- The Result: It perfectly blends the semantic understanding of dense embeddings with the exact-keyword matching power of traditional search.
2. Matryoshka Representation Learning (MRL)
The Russian Nesting Doll of AI.
Traditionally, embedding dimensions are fixed. If you use a model that outputs 1,536 dimensions, you must store 1,536 numbers for every document. This is incredibly expensive for large databases.
Matryoshka Representation Learning (used in models like OpenAI’s text-embedding-3) trains the vector so that the most important information is front-loaded at the beginning of the array.
- You can dynamically “chop off” the end of the vector.
- A 1,536-dimensional vector can be truncated to just 256 dimensions.
- Why it matters: It acts like a Russian nesting doll. The first 256 dimensions provide an excellent “small” embedding for rapid, cheap searches, while the full vector can be used later if ultimate precision is needed.
3. Vector Quantization
Shrinking vectors without losing the signal.
Even truncated vectors take up a massive amount of RAM. Quantization is a post-processing technique that compresses the numbers themselves.
- Scalar Quantization: Converts highly precise
float32numbers (which take 4 bytes each) into smallerint8numbers (1 byte each). This shrinks your database by 4x with almost zero loss in accuracy. - Binary Quantization: An extreme form where every dimension is reduced to a single bit (a
1if the number is positive, a0if negative). This shrinks memory usage by an astonishing 32x. Cohere’s latest models are specifically optimized to maintain high accuracy even when reduced to pure binary code.
Which Model Should You Choose? A Quick Guide
| Use Case | Recommended Architecture | Example Models |
|---|---|---|
| General Semantic Search (RAG) | Instruction-Tuned Dense Embeddings | text-embedding-3-large, bge-large-en |
| High-Precision / Legal / Medical | Late Interaction | ColBERTv2, Jina-ColBERT |
| Massive Scale / Budget Constrained | Matryoshka / Binary Quantized | Cohere Embed v3, text-embedding-3-small |
| E-commerce / Visual Search | Multimodal Space | CLIP, Nomic-Embed-Vision |
Conclusion
Embedding models are the unsung heroes of the AI revolution. While LLMs get all the glory for generating human-like text, it is the embedding models that allow those LLMs to actually “know” anything by retrieving the right information at the right time.
By understanding the differences between static, contextual, and multimodal models—and by leveraging advanced architectures like ColBERT and Matryoshka—you can build search systems and AI agents that are faster, cheaper, and vastly more intelligent.
The journey into the vector space is deep, but mastering it is the key to unlocking true AI capabilities. 🚀