Context is the New Prompt: The Ultimate Guide to Context Engineering
"Stop obsessing over the perfect words, and start managing the perfect state. Master the art of curating LLM memory, tools, and background knowledge."
In 2023, everyone was learning Prompt Engineering. By 2025, the industry realized that simply giving an AI a clever instruction was no longer enough. Enter the era of Context Engineering.
As Andrej Karpathy (former Director of AI at Tesla) recently put it, large language models (LLMs) are the new operating systems. In this analogy, the model is the CPU, your prompt is the executable command, and the context window is the RAM.
If you overload the RAM with junk, the system crashes.
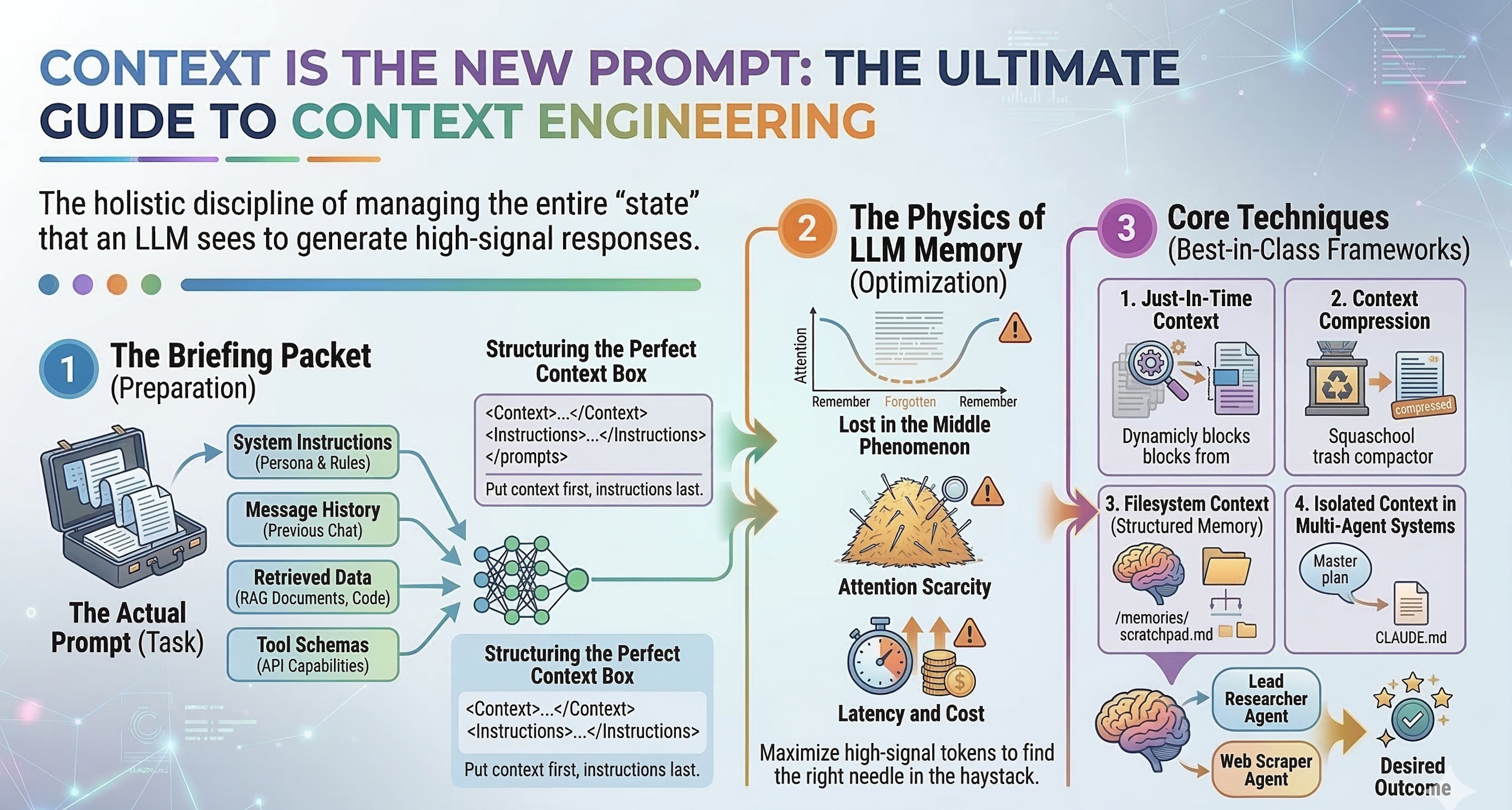
What Exactly is Context Engineering?
If Prompt Engineering is writing a clear subject line and instruction for an email, Context Engineering is preparing the entire briefing packet for a new employee on their first day.
It is the holistic discipline of managing the entire “state” that an LLM sees when it generates a response. This includes:
- System instructions (The persona and rules)
- Message history (What has been discussed so far)
- Retrieved data (RAG, documents, and codebases)
- Tool schemas (What external APIs the model can use)
- Your actual prompt (The immediate task)
Let’s explore why this matters and how to engineer context like the top AI researchers.
The Physics of LLM Memory (Why Does This Matter?)
Today’s models have massive context windows (up to 1 or 2 million tokens). So why not just dump your entire company database into the prompt and ask a question?
Because of three fundamental laws of AI physics:
- The “Lost in the Middle” Phenomenon: Research from Microsoft, Salesforce, and Anthropic shows that as context length increases, models suffer a “U-shaped” attention curve. They remember the very beginning of a prompt and the very end, but often completely ignore facts buried in the middle.
- Attention Scarcity: Even if a model can process 1 million tokens, doing so dilutes its reasoning capability. The more needles you add to the haystack, the harder it is to find the right one.
- Latency and Cost: Maxing out context windows is incredibly expensive and slow. True agents need to operate fast.
The Golden Rule of Context Engineering: Find the smallest possible set of high-signal tokens that maximize the likelihood of your desired outcome.
The Core Techniques (Best-in-Class Frameworks)
Drawing from Anthropic’s applied research and foundational architectures like the Agent Skills for Context Engineering framework, here are the tools the pros use.
1. Just-In-Time Context (Progressive Disclosure)
Instead of the “Kitchen Sink” approach, load information dynamically.
Amateur developers give an AI agent a 50-page document just in case it needs it. Context engineers give the agent a Search Tool and tell it to retrieve only what it needs, exactly when it needs it.
- How it works: Start the model with only the core mission and available tools. Let it trigger a tool (like
read_fileorweb_search) to dynamically pull relevant context into its working memory.
2. Context Compression & Hierarchical Summarization
Stop letting chat histories grow infinitely.
When an AI agent runs in a loop for hours, its context window fills up fast. Instead of blindly truncating old messages (which causes the AI to “forget”), use active compression.
SYSTEM: You are a memory manager agent.
TASK: Read the last 20 messages of this conversation.
Extract the core facts, decisions made, and user preferences into a 5-bullet summary.
Discard the raw dialogue.By feeding this compressed summary into the next step, you preserve the signal while destroying the noise.
3. Filesystem Context & Structured Memory
Give agents an external “brain”.
Anthropic recently introduced the concept of “Memory Tools” and CLAUDE.md files. If an agent is working on a long-horizon coding or research task, it shouldn’t hold its entire plan in its active context.
- The Technique: Create a local
/memoriesor/scratchpaddirectory. Teach the agent to write its plans, intermediate findings, and notes to markdown files in this directory. It can then read these files back later, freeing up space in its active context window.
4. Isolated Context in Multi-Agent Systems
Information silos are bad for humans, but great for AI.
If you have a “Lead Researcher Agent” and a “Web Scraper Agent,” they shouldn’t share the same context window.
- The Technique: The orchestrator agent creates a master plan. It then slices off only the specific context needed for the Scraper Agent and sends it over. The Scraper does its job, compresses its findings, and sends it back. This prevents sub-agents from getting confused by irrelevant big-picture data.
Structuring the Perfect Context Box
Once you have curated the right information, how you present it to the model is just as crucial. Anthropic’s public research strongly recommends using XML tags to cleanly separate context from instructions.
Here is an example of a perfectly structured prompt:
<system_role>
You are an elite financial analyst.
</system_role>
<documents>
<doc id="1">
[Insert Q3 Earnings Transcript here]
</doc>
<doc id="2">
[Insert Q4 Projections here]
</doc>
</documents>
<formatting_rules>
- Output strictly in JSON.
- If the answer is not in the documents, return {"error": "data not found"}.
</formatting_rules>
<instruction>
Based on the documents provided above, calculate the projected growth margin for Q4.
</instruction>Pro-Tip: Notice how the <instruction> comes last? LLMs exhibit “recency bias.” If you put a massive document at the bottom, the model often forgets the instruction you gave it at the top. Always put your context first, and your instructions last.
Best Practices & Pitfalls to Avoid
🟢 The “Do’s”
- Implement Graceful Degradation: If a user uploads a file that is too large, don’t crash the app. Have a fallback mechanism that automatically summarizes the text before passing it to the main agent.
- Use Markdown for Hierarchy: Models understand
# Headersand- Bullet pointsexceptionally well. Structuring raw data before feeding it into the context window improves comprehension. - Test with the “Needle in a Haystack” method: Periodically test your agent by burying a specific fact in the middle of a large context block to see if the model successfully retrieves it.
🔴 The “Don’ts”
- The “Context Stuffing” Fallacy: Do not assume that throwing 50 extra documents into the context will yield a smarter answer. It usually causes the model to hallucinate or slow down.
- Mixing Instructions with Data: Never paste user-generated text or raw data directly next to your system instructions without XML tags or delimiters. This is how Prompt Injection hacks happen.
Conclusion
We are rapidly moving away from manually tweaking verbs and adjectives in our prompts, and moving toward engineering sophisticated data pipelines that feed language models exactly what they need to succeed.
Prompt engineering gets the model to talk. Context engineering gives the model something valuable to say.
Curate ruthlessly, structure clearly, and watch your AI applications go from simple chatbots to reliable, autonomous agents.
Happy engineering! 🚀